
LIMA ليس مجرد نموذج لغوي جديد في مجال معالجة اللغة الطبيعية (NLP)، بل تجربة بحثية أعادت فتح النقاش حول كيفية بناء نماذج الذكاء الاصطناعي وتدريبها. ال
LIMA ليس مجرد نموذج لغوي جديد في مجال معالجة اللغة الطبيعية (NLP)، بل تجربة بحثية أعادت فتح النقاش حول كيفية بناء نماذج الذكاء الاصطناعي وتدريبها. النموذج، الذي طوّرته وحدة Meta AI التابعة لشركة ميتا، لفت انتباه الباحثين والمطوّرين بسبب ابتعاده عن النهج التقليدي القائم على ضخ كميات هائلة من البيانات في مراحل الضبط اللاحقة.
ما يميّز LIMA لا يرتبط فقط بنتائجه، بل بالفكرة التي ينطلق منها: الاكتفاء بعدد محدود نسبياً من الأمثلة عالية الجودة لتحقيق توافق فعّال مع المستخدمين. هذا التوجّه يطرح أسئلة أساسية حول طبيعة المعرفة التي تكتسبها النماذج اللغوية خلال مراحل تدريبها الأولى، وحدود الاعتماد على البيانات الضخمة وحدها لتحسين الأداء.

ما هو نموذج LIMA؟
LIMA هو اختصار لـ Less Is More for Alignment، أي “القليل أفضل من الكثير لتحقيق التوافق”. وهو اسم نموذج لغوي كبير (Large Language Model) مبني على أساس النموذج LLaMA الذي طوّرته Meta، ويتميّز بأنه تم تنقيحه وتكييفه باستخدام مجموعة صغيرة من الأمثلة عالية الجودة بدلاً من مجموعات ضخمة من البيانات أو التدريب عبر التعلم المعزّز بالاعتماد على التغذية الراجعة البشرية (RLHF) الذي تعتمد عليه نماذج مثل GPT-4.
النقطة الأساسية في LIMA هي أنه تم تدريب النموذج بعد مرحلة ما قبل التدريب على مجموعة من 1000 مثال مختارة بعناية فقط، وهي كمية صغيرة في مقارنة بما هو معتاد في هذا المجال، ومع ذلك أثبت قدرة قوية على أداء مهام متنوعة وفهم اللغة بشكل فعّال.

الفكرة الاساسية وراء نموذج LIMA
يتناول بحث LIMA جانباً مهمّاً في كيفية تدريب النماذج اللغوية الكبيرة، وهو أن:
المعرفة الأساسية التي يكتسبها النموذج تأتي غالباً من مرحلة ما قبل التدريب على نصوص ضخمة.
دور مرحلة “التوافق” أو “التكييف” (alignment) هو تعليم النموذج كيفية الاستجابة بصيغة مناسبة للمستخدم وليس خلق المعرفة نفسها.
وهذا ما يسميه الباحثون بـ “superficial alignment hypothesis” أو فرضية التوافق السطحي.
بمعنى آخر، الفكرة تقترح أن النموذج يستطيع أن ينتج إجابات عالية الجودة حتى بدون الاعتماد على آلاف أمثلة التدريب المُعقّدة أو عمليات التغذية الراجعة المكثّفة من البشر — وهو ما يمثل تغييراً في الفهم التقليدي لكيفية تحسين أداء نماذج الذكاء الاصطناعي.

كيف تم بناء LIMA؟
اعتمد الباحثون على نموذج LLaMA بقدرة 65 مليار معلمة كأساس، ثم:
انتقوا 1000 مثال عالي الجودة (أسئلة وإجابات) من مصادر متنوعة مثل:منتديات مثل StackExchange، مقالات تعليمية مثل WikiHow، مساهمات يدوية من الفريق البحثي
درّبوا النموذج عبر التعلم الخاضع للإشراف (supervised learning) فقط، دون استخدام التغذية الراجعة البشرية أو التعلم المعزّز.
النتيجة كانت نموذجاً يحقق أداءً موازياً أو قريباً من نماذج كبيرة مثل GPT-4 وBard في اختبارات معيّنة، رغم أنه تدريبه كان أساساً على كمية بيانات أصغر بكثير مقارنة مع هذه النماذج.
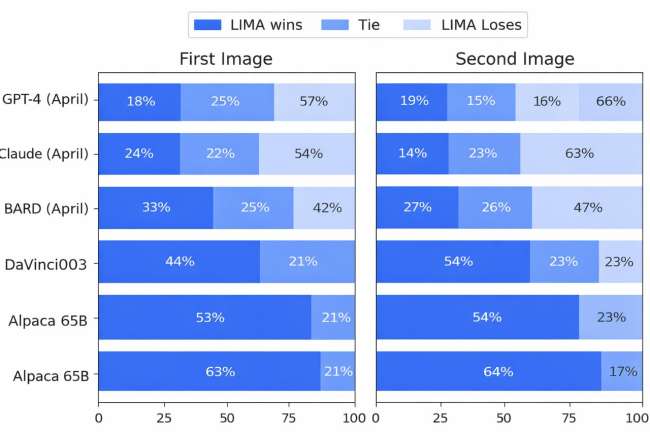
الأداء والمقارنة
في دراسة مقارنة أجراها فريق ميتا على أداء LIMA مقابل نماذج أخرى:
كانت إجابات LIMA متكافئة أو مفضّلة في بعض الحالات مقارنًة بـ GPT-4 (حوالي 43% من التقييمات البشرية).
وكان أداءه أفضل من نماذج أخرى مثل Bard وDaVinci-003 في نسب متفاوتة حسب التقييمات.
هذا لا يعني أن LIMA متفوّق دائماً، بل أنه يُظهر قدرة نموذج قوي يمكنه أداء مهام لغوية مع بيانات تدريب قليلة نسبيًا، ما يعيد ترتيب الأولويات في كيفية بناء نماذج الذكاء الاصطناعي وتدريبها.

(صورة مولدة عبر الذكاء الاصطناع).
القليل الجيد كافيًا
يمثّل LIMA خطوة بحثية مهمة في مسار تطوّر نماذج اللغة الكبيرة، ليس فقط باعتباره نموذجًا منافسًا في الأداء، بل من حيث تحديه للفكرة السائدة في عالم الذكاء الاصطناعي بأنه الأفضل دائمًا.بدلًا من ذلك، يقترح LIMA أن القليل الجيد يمكن أن يكون كافياً إذا كان النموذج الأساسي قويًا، وأن مرحلة التوافق مع المستخدم يمكن تبسيطها دون خسارة كبيرة في جودة النتائج، وهو ما قد يؤدّي إلى تغييرات مستقبلية في كيفية تصميم وتدريب النماذج اللغوية، ويُسهل دخول أطراف جديدة إلى هذا المجال دون الحاجة إلى موارد ضخمة.
لقراءة المزيد من موقعنا https://kazatech.net/
COMMENTS